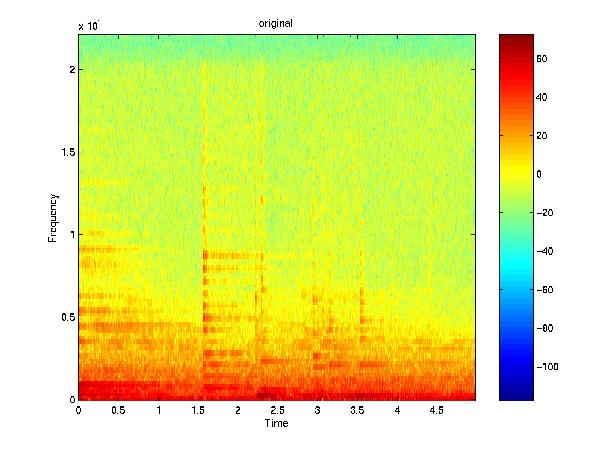
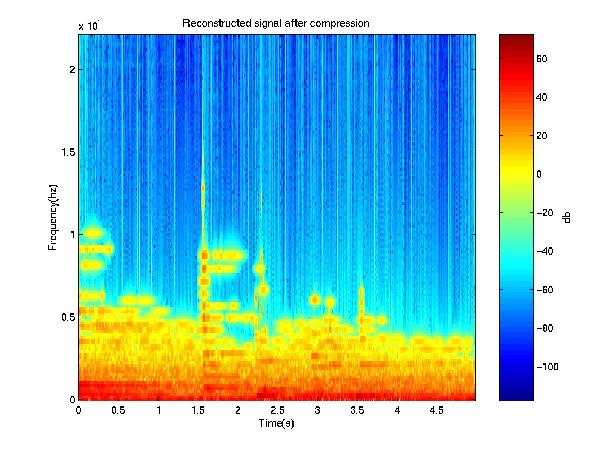
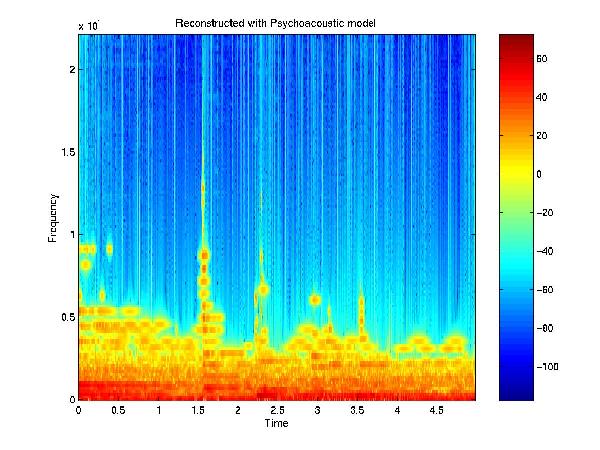
This project addresses an important issue facing the
state-of-the-art digital audio technology. Currently the data rate
associated with high fidelity wideband audio signal is enormous for
many transmission channels and storage media. The objective of this
project is to develop a high quality low bit-rate audio coder that
takes advantage of the human psychoacoustical properties, and the
true non-stationary nature of audio signals. The main challenge of
this project will be in designing non-stationary signal analysis
algorithm that will exploit the joint time and frequency correlation,
and provide an energy compact representation of the audio signal in
a fewer transform coefficients.
The objective is to develop a computationally less expensive high quality low bit-rate
audio coder to meet the increasing demand of the start-of-the-art digital audio technology.
It is hypothesized that the high quality low bit-rate coder can be achieved by exploiting
the true non-stationary characteristics of wideband audio signals, and by taking
advantage of the human psychoacoustical properties. The details of the proposed project
are outlined below in four stages:
STAGE 1:
To start with, the wideband audio signal will be sampled and quantized.
The audio signal at this stage is converted into a digital audio, typically of PCM format.
The data rate of a high fidelity audio signal is about 1.4 Mb/s for a 44.1 kHz sampling
rate and 16 bits/sample quantization. This data rate is simply too high for many
transmission channels and storage media. As a result, coding algorithms that reduce the
output data rate have received much attention. These algorithms compress the audio signal
by exploiting the statistical, temporal and spatial redundancies that are an integral part
of any audio signal. A brief review on commonly used compression schemes, and a detailed
description of the proposed compression scheme are discussed in stage 2.
STAGE 2:
Two fundamentally different techniques are available for the
compression of PCM audio data: time domain and frequency domain
coding. In time domain coding, the temporal redundancy between audio
samples is exploited. The motivation for time domain coding of audio
signals is to represent a orrelated waveform in terms of difference
samples, such that one can maintain the same signal-to-noise ratio
(SNR) at a reduced bit rate. Frequency domain coders are designed to
identify and remove redundancy in frequency domain. A common feature
of all frequency domain coders is the transformation technique
used. The mapping into frequency domain is accomplished by a
transform, resulting in a transform coder, or by subband
decomposition, resulting in a subband coder.
In case of audio signals, the instruments used as well as the music style affect
their spectral content, and the spectra varies with time. It is evident that the audio
signals are non-stationary random processes, and it is difficult to analyze such
signals either in time or frequency domain alone. Popular coding techniques such as
discrete cosine transform (a transform coding technique) and linear predictive coding
(a time domain coding technique) do not yield optimal performance in compressing
non-stationary audio data.
In this project, we propose to develop a transform coder that takes into account
the non-stationary behavior of audio signals. Non-stationary signals could be analyzed
by using joint time-frequency (TF) transformations. In a TF transform the energy of a
signal is mapped into a two-dimensional time and frequency plane. There are a various
types of quadratic TF distributions, and it is difficult to determine the best (or optimal)
one for analyzing audio signals. One way of providing an optimal analysis is by designing
a TF transformation totally adapted to the signal characteristics, and we call such a
technique as adaptive TF transformation (ATFT).
The main focus of this project will be in designing the ATFT algorithm suitable for audio
signals. The ATFT algorithm will be based on the idea of signal decomposition. Once the
signal is decomposed into components, the ATFT of the signal will be constructed by
combining the commonly used quadratic distributions (e.g., Wigner distributions) of each
components. The key to the successful design of ATFT lies in the selection of the signal
decomposition algorithm. The components obtained depend on the basis functions used. For
example, the basis function of the Fourier transform decomposes the signal into tonal
components, and the basis function of the wavelet transform decomposes the signal into
components with good time and scale properties. The components obtained by decomposing a
signal using basis functions with good TF properties may be ideal candidate for ATFT coding.
It is known in the literature that the Guassion functions provide an optimal TF resolution.
Therefore the signal decomposition in ATFT will be performed by projecting the signal onto
an overcomplete collection of Guassian basis functions. Now the decomposed signal
components represented in terms of ATFT coefficients will contain the joint time and
frequency correlation information.
Also the signal decomposition concept inherent in ATFT will find application in an
important area of audio signal processing known as adaptive denoising.
Adaptive denoising is a novel technique for reducing noise in cases where the spectra
of the signal and noise overlap significantly, and forms the basis for high quality
audio reproduction. Noise (either white or colored) tend to take low magnitude
values on ATFT coefficients. The SNR of an audio signal could be significantly improved
by reconstructing the signal back by suppressing low magnitude ATFT coefficients.
The threshold to decide low magnitude ATFT coefficients could be made signal adaptive or
it could be based on a hard decision. The ATFT coefficients left out after denoising
will be a compact representation of the audio signal. In stage 3 discussed below the
ATFT coefficients will be further processed in order to achieve a low bit-rate coding.
STAGE 3:
The ATFT coefficients may contain perceptually redundant values. Psychoacoustics provides
an analytic model of auditory perception. This model of the human auditory system
establishes a framework under which the ATFT coefficients containing redundant audio
information can be identified. The perceptually relevant ATFT coefficients will be
re-quantized. The re-quantized output will now denote the low bit-rate output of the
audio coder. The re-quantized output could be further compressed by using entropy-based
coding techniques such as Huffman coding. The Huffman coding stage is just an option,
and may be excluded in computationally intensive applications.
STAGE 4:
The ATFT coder could be implemented on a hardware. Processing digital audio and
performing ATFT coding will require a significant amount of memory, computation,
and internal data transfer. The project could be cost-effectively implemented using
digital signal processing (DSP) chips, which are microprocessors tailored to implement
signal processing tasks efficiently. Features that make DSP-based platforms ideally
suited for implementing ATFT coder include: low-power consumption, single-cycle
multiply and multiply-accumulate (MAC) for fast calculation of ATFT coefficients
and quantization, and various memory access modes for efficient data transfer.
The output of the ATFT coder could either be send through a bandlimited communication
network or massively stored in a digital media depending on the application in hand.